
One of the questions that we at the International Data Corporation are asked is what impact technologies like Artificial Intelligence (AI) will have on jobs. Where are there likely to be job opportunities in the future? Which jobs (or job functions) are most ripe for automation? What sectors are likely to be impacted first? The problem with these questions is that they misunderstand the size of the barriers in the way of system-wide automation: the question isn’t only about what’s technically feasible. It’s just as much a question of what’s legally, ethically, financially and politically possible.
That said, there are some guidelines that can be put in place. An obvious career path exists in being on the ‘other side of the code’, as it were – being the one who writes the code, who trains the machine, who cleans the data. But no serious commentator can leave the discussion there – too many people are simply not able to or have the desire to code. Put another way: where do the legal, financial, ethical, political and technical constraints on AI leave the most opportunity?
Firstly, AI (driven by machine learning techniques) is getting better at accomplishing a whole range of things – from recognising (and even creating) images, to processing and communicating natural language, completing forms and automating processes, fighting parking tickets, being better than the best Dota 2 players in the world and aiding in diagnosing diseases. Machines are exceptionally good at completing tasks in a repeatable manner, given enough data and/or enough training. Adding more tasks to the process or attempting system-wide automation requires more data and more training. This creates two constraints on the ability of machines to perform work: 1) machine learning requires large amounts of (quality) data and 2) training machines requires a lot of time and effort (and therefore cost). Let’s look at each of these in turn – and we’ll discuss how other considerations come into play along the way.
Speaking in the broadest possible terms, machines require large amounts of data to be trained to a level to meet or exceed human performance in a given task. This data enables the bot to learn how best to perform that task. Essentially, the data pool determines the output.
However, there are certain job categories which require knowledge of, and then subversion of, the data set – jobs where producing the same ‘best’ outcome would not be optimal. Particularly, these are jobs that are typically referred to as creative pursuits – design, brand, look and feel. To use a simple example: if pre-Apple, we trained a machine to design a computer, we would not have arrived at the iMac, and the look and feel of iOS would not become the predominant mobile interface.
This is not to say that machines cannot create things. We’ve recently seen several ML-trained machines on the internet that produce pictures of people (that don’t exist) – that is undoubtedly creation (of a particularly unnerving variety). The same is true of the AI that can produce music. But those models are trained to produce more of what we recognise as good. Because art is no science, a machine would likely have no better chance of producing a masterpiece than a human. And true innovation, in many instances, requires subverting the data set, not conforming to it.
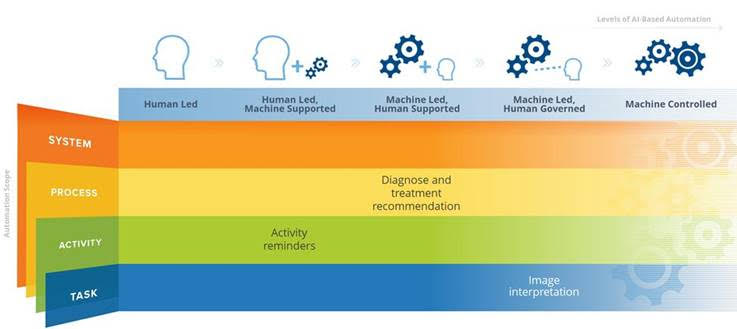
Secondly, and perhaps more importantly, training AI requires time and money. Some actions are simply too expensive to automate. These tasks are either incredibly specialised, and therefore do not have enough data to support the development of a model, or very broad, which would require so much data that it will render the training of the machine economically unviable. There are also other challenges which may arise. At the IDC, we refer to the Scope of AI-Based Automation. In this scope:
- A task is the smallest possible unit of work performed on behalf of an activity.
- An activity is a collection of related tasks to be completed to achieve the objective.
- A process is a series of related activities that produce a specific output.
- A system (or an ecosystem) is a set of connected processes.
As we move up the stack from task to system, we find different obstacles. Let’s use the medical industry as an example to show how these constraints interact. Medical image interpretation bots, powered by neural networks, exhibit exceptionally high levels of accuracy in interpreting medical images. This is used to inform decisions which are ultimately made by a human – an outcome that is dictated by regulation. Here, even if we removed the regulation, those machines cannot automate the entire process of treating the patient. Activity reminders (such as when a patient should return for a check-up, or reminders to follow a drug schedule) can in part be automated, with ML applications checking patient past adherence patterns, but with ultimate decision-making by a doctor. Diagnosis and treatment are a process that is ultimately still the purview of humans. Doctors are expected to synthesize information from a variety of sources – from image interpretation machines to the patient’s adherence to the drug schedule – in order to deliver a diagnosis. This relationship is not only a result of a technicality – there are ethical, legal and trust reasons that dictate this outcome.
There is also an economic reason that dictates this outcome. The investment required to train a bot to synthesize all the required data for proper diagnosis and treatment is considerable. On the other end of the spectrum, when a patient’s circumstance requires a largely new, highly specialised or experimental surgery, a bot will unlikely have the data required to be sufficiently trained to perform the operation and even then, it would certainly require human oversight.
The economic point is a particularly important one. To automate the activity in a mine, for example, would require massive investment into what would conceivably be an army of robots. While this may be technically feasible, the costs of such automation likely outweigh the benefits, with replacement costs of robots running into the billions. As such, these jobs are unlikely to disappear in the medium term.
Thus, based on technical feasibility alone our medium-term jobs market seems to hold opportunity in the following areas: the hyper-specialised (for whom not enough data exists to automate), the jack-of-all-trades (for whom the data set is too large to economically automate), the true creative (who exists to subvert the data set) and finally, those whose job it is to use the data. However, it is not only technical feasibility that we should consider. Too often, the rhetoric would have you believe that the only thing stopping large scale automation is the sophistication of the models we have at our disposal, when in fact financial, regulatory, ethical, legal and political barriers are of equal if not greater importance. Understanding the interplay of each of these for a role in a company is the only way to divine the future of that role.



