
In the race to integrate artificial intelligence into every corner of the workplace, a critical question often gets lost in the hype: Is this AI actually making us more productive? Standard benchmarks can tell you how well a large language model (LLM) performs on a multiple-choice exam or a logic puzzle, but they fall short of measuring its ability to handle the messy, multilingual, and complex tasks that define a modern workday.
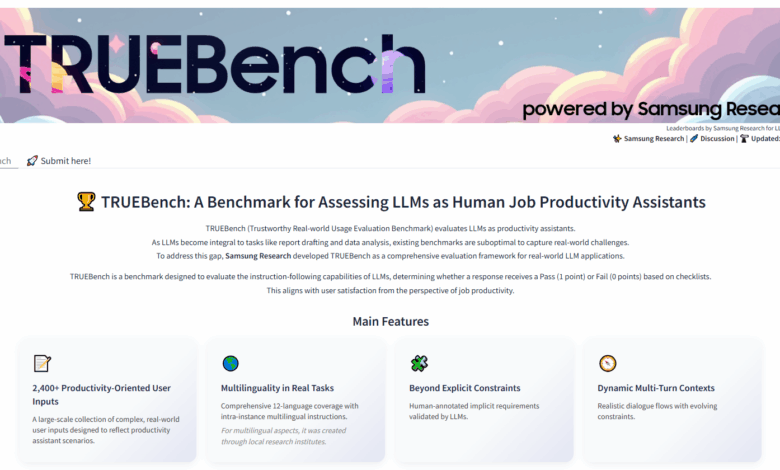
Samsung is aiming to solve this with TRUEBench (Trustworthy Real-world Usage Evaluation Benchmark), a new proprietary benchmark designed from the ground up to evaluate how AI models perform in practical business scenarios. Unveiled today by Samsung Research, the new testing suite ditches abstract Q&As for a comprehensive evaluation of tasks that employees actually do, from summarizing lengthy reports to translating nuanced business communications.
“Samsung Research brings deep expertise and a competitive edge through its real-world AI experience,” said Paul (Kyungwhoon) Cheun, CTO of the DX Division at Samsung Electronics and Head of Samsung Research. “We expect TRUEBench to establish evaluation standards for productivity and solidify Samsung’s technological leadership.”
The Problem with Current AI Benchmarks
For years, the AI industry has relied on benchmarks that, while useful for academic purposes, struggle to reflect the realities of a corporate environment. Most existing tests are heavily English-centric, limiting their relevance for global companies. Furthermore, they are often structured around simple, single-turn question-and-answer formats, which bear little resemblance to the ongoing, multi-step dialogues required for complex projects.
This gap has created a challenge for businesses trying to assess which AI tool is the right fit. An LLM that excels at standardized tests might flounder when asked to analyze a 20,000-character document and generate a concise summary for a team in another country. Samsung developed TRUEBench to directly address these limitations.
A Benchmark Built for Business
Drawing on its own internal use of AI for productivity, Samsung designed TRUEBench to be a more realistic measure of an LLM’s utility. The benchmark is built around a total of 2,485 test sets covering 10 major categories and 46 sub-categories of common enterprise tasks, including:
- Content Generation: Creating reports, emails, and other documents.
- Data Analysis: Interpreting and drawing conclusions from data sets.
- Summarization: Condensing long documents into key takeaways.
- Translation: Accurately translating content between languages.
Critically, TRUEBench is inherently multilingual, supporting 12 different languages and even evaluating cross-linguistic scenarios where a task might start in one language and require an output in another. The length of the test inputs also varies dramatically—from as short as eight characters to over 20,000—to simulate everything from a quick request to a deep document analysis.
How Humans and AI Teamed Up to Write the Rules
One of the most innovative aspects of TRUEBench is how its evaluation criteria were developed. Samsung recognized that to test for real-world performance, the benchmark needed to account for the implicit needs of users—the things you expect an assistant to understand without having to spell them out in every instruction.
To achieve this, Samsung Research employed a unique collaborative process between human experts and AI.
- Human Creation: First, human annotators created the initial set of evaluation criteria for a given task.
- AI Review: An AI model then reviewed these human-created rules, checking for errors, logical contradictions, or unnecessary constraints that might not apply in a real-world context.
- Human Refinement: The human annotators then took the AI’s feedback and refined the criteria.
This iterative loop was repeated to create increasingly precise and realistic evaluation standards. This human-AI collaboration minimizes the subjective bias that can creep into human-only evaluations and ensures a consistent, reliable scoring system.
The scoring itself is unforgiving. For an AI model to pass a specific test within TRUEBench, it must satisfy all of the detailed conditions for that task. There is no partial credit, enabling a more detailed and precise final score that truly reflects the model’s capabilities.
Open for Comparison on Hugging Face
In a move toward transparency, Samsung has made TRUEBench’s data samples and leaderboards publicly available on the open-source platform Hugging Face. This allows developers, businesses, and researchers to compare the performance of up to five different models side-by-side. The platform not only shows performance scores but also publishes data on the average length of a model’s response, allowing for a simultaneous comparison of both performance and efficiency—a key metric for real-time applications.
By launching TRUEBench, Samsung is making a clear statement: the true measure of an AI’s value isn’t its academic knowledge, but its ability to get real work done. For companies navigating the complex landscape of AI adoption, this new benchmark could become an essential tool for separating the truly productive models from the merely clever ones.



